

Introduction To YOLO — You Only Look Once
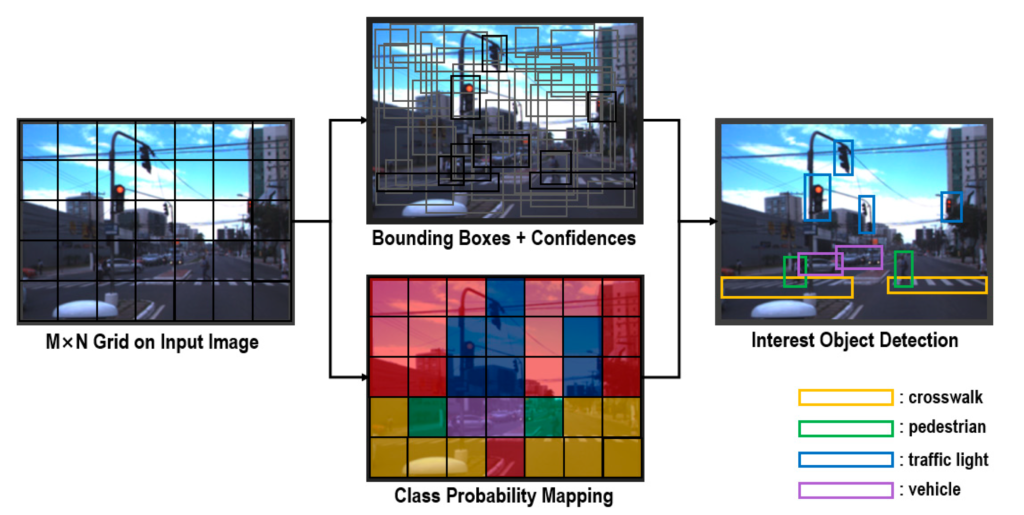
All of the previous object detection algorithms use regions to localize the object within the image. The network does not look at the complete image. Instead:
- It Intakes an image and divides it in a grid of S X S (where S is a natural number)
- Each pixel in the image can be responsible for a finite number of (5 in our case) bounding box predictions. A pixel is taken responsible for prediction when it is the center of the object detected. Out of all detected boxes, It is taken responsible for the detection of only one object, and other detections are rejected.
- It predicts C conditional class probabilities (one per class for the likeliness of the object class).
Notes:
Total detections to be done per image=S X S((B*5)+C)
- S X S= Total number of images YOLO divides the Input
- B is the Number of Bounding boxes Detected all over the image(Without any threshold consideration).
- B*5= For each bounding box, 5 elements are detected:
1. Detected Objects Center coordinates(x,y)
2. Height and Width
3. Confidence score. - C=Conditional probability for the Number of Classes.
– What is the Confidence threshold?
The threshold for minimum confidence the model has on a detected object (box confidence score)
– How is the box confidence score calculated?
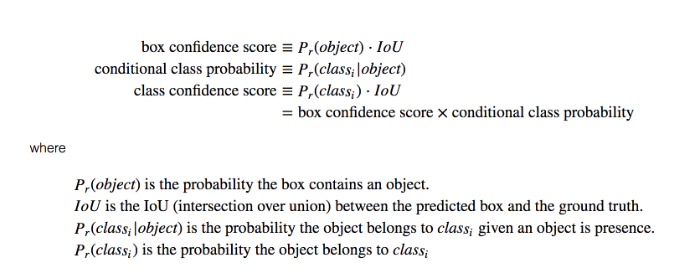
However, most of these boxes have low confidence scores and if we set a threshold say 30% confidence, we can remove most of them as shown in the example below
YOLO requires a Neural Network framework for training and for this we have used DarkNet
Let’s Learn about different YOLO versions:
– YOLOv1:
has 26 layers in total, with 24 Convolution Layers followed by 2 Fully Connected layers. The major problem with YOLOv1 is
its inability to detect very small objects.
– YOLO9000 / YOLOv2:
- Inclusion of batch Normalization layers after each Conv Layer
- It has 30 layers in comparison to YOLOv1’s 26 layers.
- Anchor Boxes were introduced.
Notes:
Anchor boxes are predefined boxes provided by the user to Darknet which gives the network an idea about the relative position and
dimensions of the objects to be detected. It must be calculated using the training set Objects.
- No fully connected layer present
- Random dimensions were taken for training images ranging from 320–608
- Multiple labels might be provided to the same objects, but still a multiclass problem (WordTree concept)
i.e. either the parent or child be the final label and not both. - Still bad with small objects
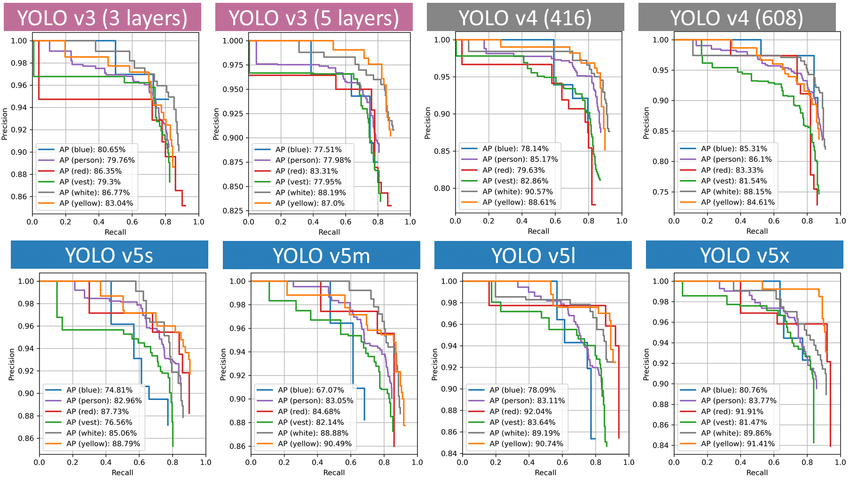
– YOLOv3:
- 106 layers neural network
- Detection on 3 scales for detecting objects of small to very large size
- 9 anchor boxes taken; 3 per scale. Hence more bounding boxes are predicted than YOLOv2 & YOLOv1
- Multi-class problem turned into Multi-Label problem
- Certain changes in the Error function.
- Quite good with small objects
– YOLOv4:
- There are a huge number of features
- Some features operate on certain models exclusively and for certain problems exclusively, or only for small-scale datasets:
- There are a huge number of features
- Some features operate on certain models exclusively and for certain problems exclusively, or only for small-scale datasets
- ~65 frames per second (FPS)
– YOLOv5:
- 0.007 seconds per image
- ~140 frames per second (FPS)
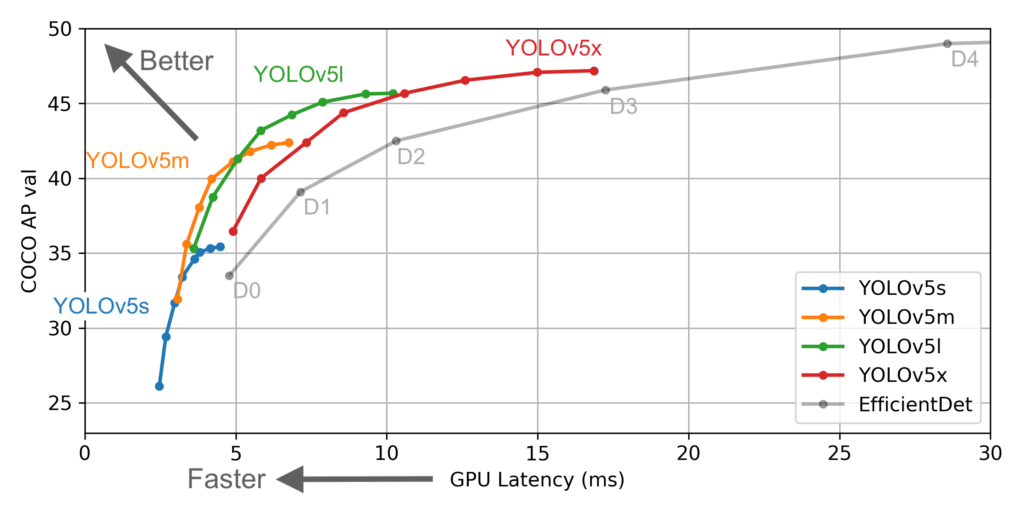
Conclusion:
YOLOv5 is orders of magnitude faster (~140 frames per second) than other object detection algorithms. The limitation of the YOLO algorithm is that it struggles with small objects within the image, for example, it might have difficulties in detecting a flock of birds.
This is due to the spatial constraints of the algorithm.
In the next part, we will learn about the Implementation of HUMAN CROWD DETECTION and How to solve the problem of Detection Small Objects in YOLOv5
References:
- Official repository – declares the latest version of YOLOv4 / Scaled-YOLOv4: https://github.com/pjreddie/darknet#darknet
- Official YOLOv4 repository: https://github.com/AlexeyAB/darknet
- Official paper – YOLOv4: https://arxiv.org/abs/2004.10934
- Official paper – Scaled-YOLOv4: https://arxiv.org/abs/2011.08036
- Taiwanese government uses YOLOV4: https://www.taiwannews.com.tw/en/news/3957400
- Official paper – YOLOv5: https://docs.ultralytics.com/
- Official repository – YOLOv5: https://github.com/ultralytics/yolov5
