

An enterprise data warehouse brings the data together and makes it available for querying and data processing, it should consolidate data from many sources. All data in a data warehouse should be available for querying and it’s important to ensure that those queries are quick.
Another reason to consolidate all of your data besides standardizing the format and making it available for querying is to make sure the query results are meaningful. You want to make sure the data is clean, accurate, and consistent. Also, as the business data requirements continue to grow, you want to make sure that a data warehouse can deal with datasets that don’t fit into memory.
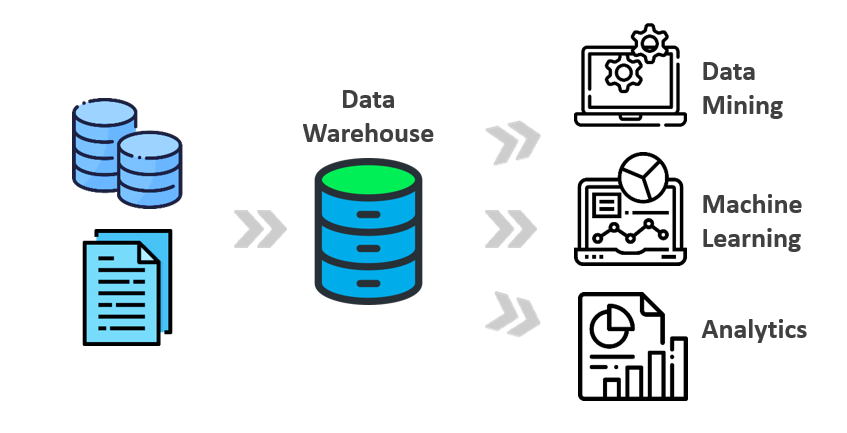
Next, your data warehouse is not productive if it allows you to do queries but doesn’t support rich visualization and reporting. It is important for analysts to carry out ad-hoc queries faster because you want the data warehouse to increase the speed at which your business makes decisions. There is totally a better way to manage this overhead and deal with these challenges. What about a serverless data warehouse?
Let’s introduce BigQuery, a data warehouse solution on the Google Cloud Platform.
What’s BigQuery GCP Service
BigQuery is Google Cloud’s fully managed, petabyte-scale, and cost-effective analytics data warehouse that lets you run analytics over vast amounts of data in near real-time. No upfront costs, self-optimizing storage, NoOps, no clusters, no vacuuming, per second billing, self-scaling, separate state & compute. Let’s discuss these features in detail.
BigQuery Features and Services
As we mentioned in the previous section and unlike traditional data warehouses, BigQuery has features like geospatial and Machine learning built-in, it also provides capabilities to stream data in so you can analyze your data in near real-time. Because it’s part of Google Cloud, you get all of the security benefits that the cloud provides
while also being able to share data sets inquiries. BigQuery supports standard SQL queries and is compatible with ANSI SQL 2011.
In addition, for sure you want the data warehouse to be serverless and fully no-Ops, you don’t want to be limited to clusters that you need to maintain or indexes that you need to find too. Because you don’t have to be worried about all of those things, you can spend your time thinking about how to get better insights from your data.
Here’re more interesting services to know:
1. Dealing with External Data Sources
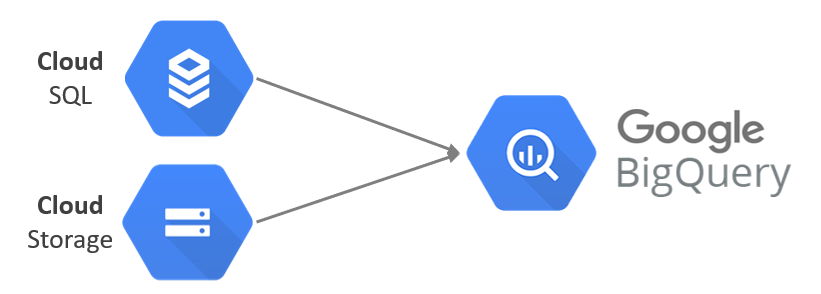
BigQuery offers support for querying data directly from an external data source or also as known as a federated data source in which data is not stored in BigQuery, but in storage like Bigtable, Cloud Storage, Google Drive, and Cloud SQL. Using BigQuery instead of loading or streaming the data, you create a table that references the external data source.
2. Tables and Views in BigQuery
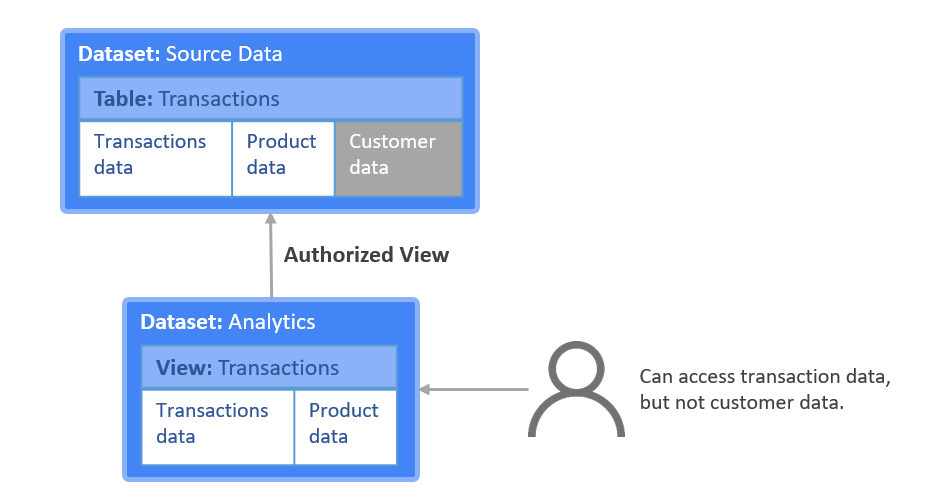
Database tables and views function the same way in BigQuery as they do in a traditional data warehouse allowing BigQuery to support queries written a standard SQL. We are going to talk about the tables in the next section.
3. Grants and Permissions
Cloud Identity and Access Management, or Cloud IAM, is used to grant permission to perform specific actions BigQuery. This replaces the SQL grant and revokes statements that are used to manage access permissions in traditional SQL databases.
4. Storage and Resources
BigQuery allocates storage and query resources dynamically based on your usage patterns. Each query uses some number of what are called slots. Slots are units of computation that comprise a certain amount of CPU and RAM.
Schema and Tables in BigQuery
1. Tables
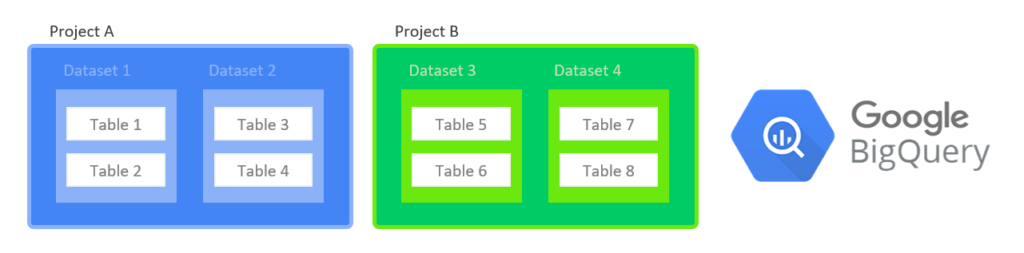
BigQuery organizes data tables into units called datasets. These data sets are scoped to your GCP project. These multiple scopes, projects, datasets, and tables can help you structure your information logically. You can use multiple datasets to separate tables pertaining to different analytical domains and you can use project-level scoping to isolate datasets from each other according to your business needs.
The project is what the billing is associated with.
You can separate the cost of storage and the cost of queries, by separating projects A and B.
2. Schemas
To use a data warehouse, an analyst needs to know the schema of the data. Designing efficient schemas that scale is a core job responsibility for any data engineering team. BigQuery hosts over 100 public datasets and schemas for you to explore.
An additional thing to know is that the schema auto-detection is available when you load data into BigQuery, and when you query an external data source. When auto-detection is enabled, BigQuery starts the inference process by selecting a random file in the data source and scanning up to 100 rows of data to use as a representative sample. BigQuery then examines each field and attempts to assign a data type to that field based on the values in the sample.
Schema auto-detection is not used with Avro files, Parquet files, ORC files, Firestore export files, or Datastore export files.
To enable schema auto-detection when loading data:
- Cloud Console: in the Schema section, for Auto detect, check the Schema and input parameters option.
- Classic BigQuery web UI: in the Schema section, check the Automatically detect option.
bq: use thebq loadcommand with the--autodetectparameter.
Finally, let’s take a look at how easy it is to query large datasets in BigQuery.
Querying Data
Querying native tables is the most common case and the most performant way to use BigQuery. BigQuery is most efficient when working with data contained in its own storage service, the storage service and the query service work together to internally organize the data to make queries efficient over huge datasets of terabytes and petabytes in size.
The query service can also run query jobs on data contained in other locations such as tables in CSV files hosted on cloud storage. So you can query data and external tables or from external sources without loading it into BigQuery, these are called Federated queries.
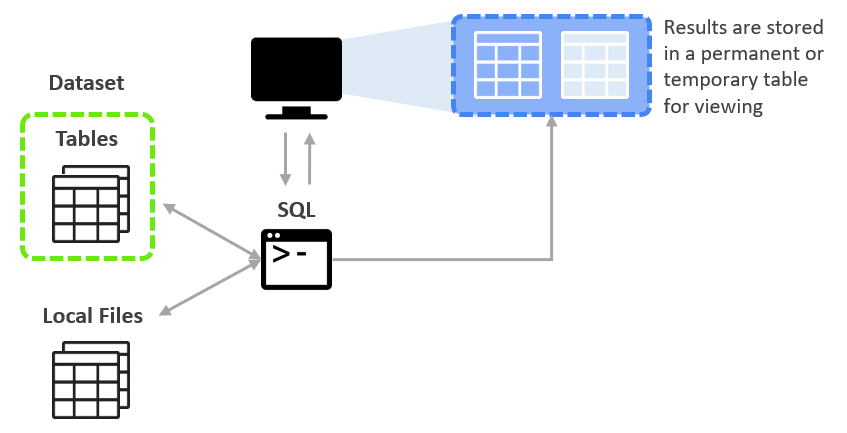
The query service puts the results into a temporary table and the user interface pulls and displays the data in the temporary table. This temporary table is stored for 24 hours, so if you run the exact same query again, and if the results would not be different then BigQuery will simply return a pointer to the cached results.
Uploading queryable data
In this section, you pull in some public data into your project so you can practice running SQL commands in BigQuery.
1. Open BigQuery Console
In the Google Cloud Console, select Navigation menu > BigQuery:
— The Welcome to BigQuery in the Cloud Console message box opens.
— Click Done.
— The BigQuery console opens.
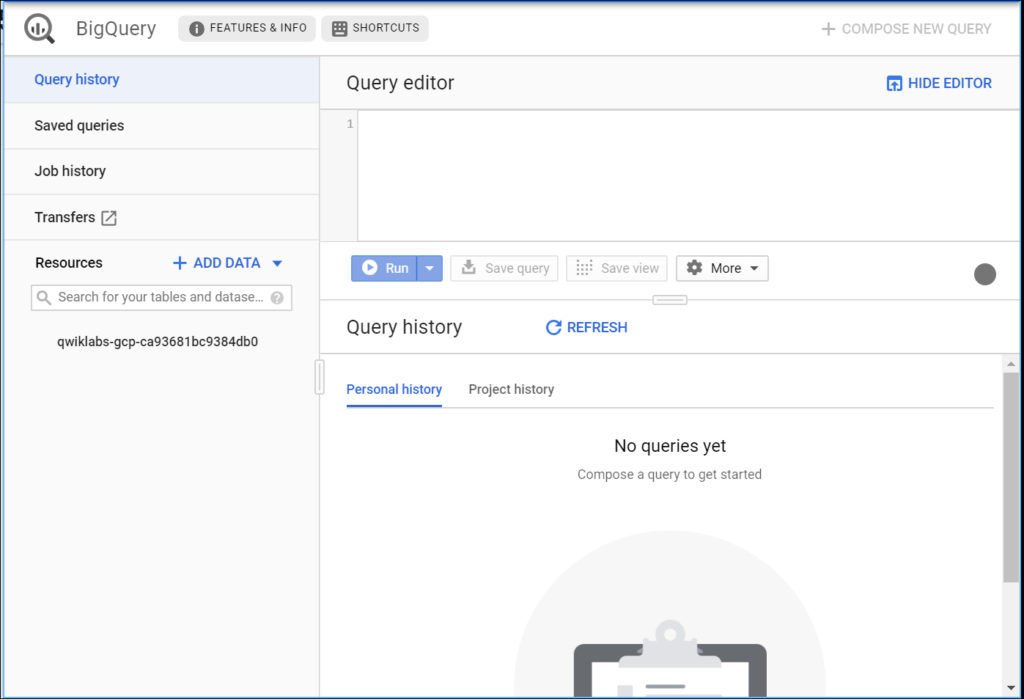
— The left pane of the console is the “Navigation panel”. Apart from the self-explanatory query history, saved queries, and job history, there is the Resources tab.
2. Uploading queryable data
In this section, you pull in some public data into your project so you can practice running SQL commands in BigQuery.
— Click on the + ADD DATA link then select Explore public datasets:
— In the search bar, enter “London“, then select the London Bicycle Hires tile, then View Dataset.
— A new tab will open, and you will now have a new project called bigquery-public-data added to the Resources panel:
— Click on bigquery-public-data > london_bicycles > cycle_hire. You now have data that follows the BigQuery paradigm:
- Google Cloud Project →
bigquery-public-data - Dataset →
london_bicycles - Table →
cycle_hire
— Now that you are in the cycle_hire table, in the center of the console, click the Preview tab. Your page should resemble the following:
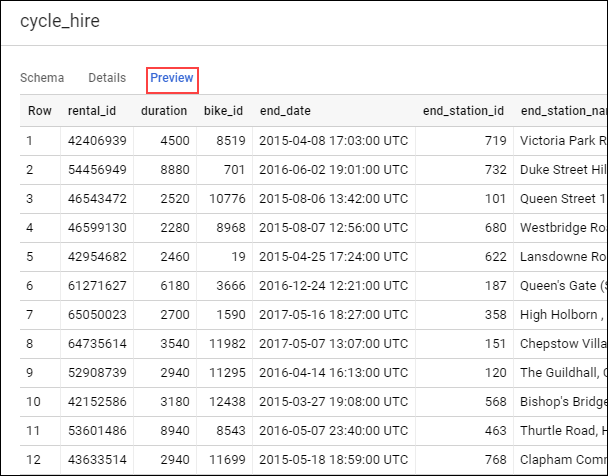
Inspect the columns and values populated in the rows. You are now ready to run some SQL queries on the cycle_hire table.
3. Running SELECT, FROM, and WHERE in BigQuery
You now have a basic understanding of SQL querying keywords. Let’s run some SQL commands using this service. Before we get too deep, let’s first run a simple query to isolate the end_station_name column.
— Copy and paste the following command into the Query editor:
SELECT end_station_name FROM `bigquery-public-data.london_bicycles.cycle_hire`;— Then click Run.
After ~20 seconds, you should be returned with 24369201 rows that contain the single column you queried for: end_station_name. Why don’t you find out how many bike trips were 20 minutes or longer?
— Click COMPOSE NEW QUERY to clear the Query editor, then run the following query that utilizes the WHERE keyword:
SELECT * FROM `bigquery-public-data.london_bicycles.cycle_hire` WHERE duration>=1200;This query may take a minute or so to run. SELECT * returns all column values from the table. Duration is measured in seconds, which is why you used the value 1200 (60 * 20).
Arriving to here, you learned the fundamentals of SQL and how you can apply keywords and run queries in BigQuery and you were taught the core concepts behind projects, databases, and tables.
Summary
We argue that doing data engineering in the Cloud is advantageous because you can separate compute from storage and you don’t have to worry about managing infrastructure and even software. This allows you to spend more time on what matters, getting insights from data. We introduced data warehouses and BigQuery as the data warehouse solution on Google Cloud in addition to the features and the very powerful services of BigQuery. The hope is that this article can serve as a starting point when you build your data warehouse project.
